📊 Full opportunity report: VigilSAR Benchmark: There Is No Best Model on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The VigilSAR Benchmark shows there is no universally best AI model for defense and intelligence applications. Rankings vary based on user profiles, with emphasis on deployment, safety, and compliance. This challenges the idea that capability alone determines model superiority.
The VigilSAR Benchmark has released its initial findings, confirming that there is no single AI model that is best across all defense-relevant axes. The benchmark emphasizes deployment readiness, safety, and compliance, highlighting that suitability depends on the user’s profile and needs. This challenges the common perception that the most capable model is always the optimal choice, especially in regulated or sensitive environments.
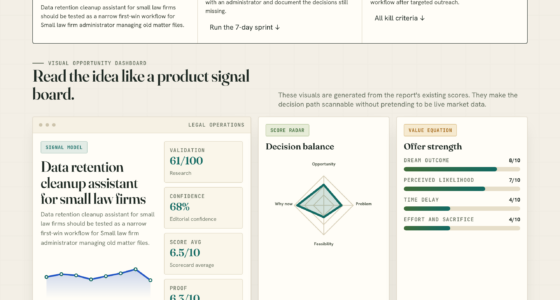
The VigilSAR Benchmark evaluates models on five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. It assesses models across eight knowledge domains relevant to defense and intelligence, explicitly excluding offensive or harmful capabilities such as weaponization or exploit generation. The benchmark’s unique feature is its re-ranking of models based on different user profiles, including cloud-centric, sovereign, and compliance-focused perspectives.
According to the developers, the core finding is that a model’s ranking varies significantly depending on the context. For example, a model that scores highest on raw capability in a cloud environment might fall behind in a sovereign setting where on-premises deployment and compliance are paramount. This underscores that “the best” model is highly dependent on the specific deployment scenario and user requirements.
The benchmark also prioritizes safety and compliance, rewarding models that behave reliably and adhere to legal frameworks like the EU AI Act and GDPR. It explicitly avoids scoring offensive capabilities, focusing instead on trustworthy performance in defense-relevant tasks. The developers stress that this early-stage effort aims to provide a more nuanced, context-aware approach to AI evaluation in sensitive sectors.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Implications for Defense and Intelligence AI Selection
The VigilSAR Benchmark’s findings have significant implications for organizations selecting AI models for defense and intelligence use. It demonstrates that relying solely on capability rankings can be misleading, as deployment context, regulatory compliance, and safety considerations are equally critical. This could influence procurement strategies, encouraging buyers to adopt multi-criteria assessments tailored to their operational needs.
Furthermore, the benchmark’s emphasis on user profiles and re-ranking models underscores the importance of context-aware evaluation frameworks. It challenges the dominance of capability-centric leaderboards and advocates for a more holistic, responsible approach to AI deployment in sensitive environments.

FDE: The Forward Deployed Engineer: Architecting the Last Mile of Enterprise AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations and Scope of the VigilSAR Benchmark
The VigilSAR Benchmark is still in its early development phase, with methodologies subject to refinement. It explicitly excludes offensive or weaponized capabilities, focusing instead on defense-relevant, trustworthy knowledge work. Its scoring system prioritizes safety, compliance, and deployability, aiming to serve regulated and sovereign buyers.
Most existing AI benchmarks emphasize raw performance and capability, often neglecting deployment realities and legal constraints. VigilSAR seeks to fill this gap by providing a multi-dimensional assessment tailored to defense and intelligence contexts. Its approach reflects a broader shift towards responsible AI evaluation, especially in sensitive sectors where safety and compliance are non-negotiable.
It is important to note that the current results are preliminary, and the methodology will evolve as the benchmark matures and more models are evaluated.
“There is no one-size-fits-all model. Suitability depends on the specific deployment context and user needs.”
— Thorsten Meyer, developer of VigilSAR

AI Forensics
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Methodology and Adoption
The development process of the VigilSAR methodology and its adoption by defense and intelligence agencies are ongoing. As the benchmark evolves, its scoring criteria may be updated to incorporate new data and insights. The practical effects of re-ranking models based on user profiles in real-world procurement are yet to be fully understood.
Further clarification is needed on how the benchmark will adapt to emerging AI capabilities and whether additional evaluation axes or standards will be introduced over time.

Adversarial AI Attacks, Mitigations, and Defense Strategies: A cybersecurity professional's guide to AI attacks, threat modeling, and securing AI with MLSecOps
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Benchmark Development and Community Engagement
The VigilSAR team intends to expand its evaluation scope by including more models and refining its scoring methodology. Collaboration with defense and intelligence stakeholders will be prioritized to ensure the benchmark remains relevant and practical. Updates are expected throughout 2024, with potential integration into procurement processes and industry standards.
Additionally, the team plans to publish guidelines to assist organizations in interpreting and applying the benchmark results effectively within their specific operational contexts.

AI Prompt Engineering: Foundations of Communication with LLMs – Building Generative AI and Agentic AI Prompt Systems Across Development, Testing, and Deployment (AI Engineering)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why does the VigilSAR Benchmark claim there is no ‘best’ model?
The benchmark shows that model suitability depends on the specific deployment scenario, user needs, and regulatory requirements. No single model outperforms others across all axes relevant to defense and intelligence use cases.
How does VigilSAR differ from traditional AI leaderboards?
Unlike traditional leaderboards that focus solely on raw capability, VigilSAR evaluates models on multiple axes including safety, reliability, and deployability, and re-ranks them based on user profiles.
Is the VigilSAR Benchmark finalized?
No, it is still in early development. Its methodology and scope are subject to change as more models are evaluated and feedback is incorporated.
Who should use the VigilSAR Benchmark?
Defense, intelligence, and regulated organizations seeking a more holistic, context-aware evaluation of AI models for deployment in sensitive environments.
Will the benchmark include offensive or weaponized capabilities in the future?
No, the current scope deliberately excludes offensive, weaponization, or exploit generation capabilities to focus on trustworthy, defense-relevant knowledge work.
Source: ThorstenMeyerAI.com